문제이해
query를 따로 때서 info를 하나씩 돌면서 처음에는 점수를 확인하고 다음에는 '-' 표시를 확인하고 다음에는 같은 문자가 있는지 확인하면서 만약에 모든 과정을 통과하면 그 query의 성공+1 을 하는 방식을 생각했습니다.(다른사람의 풀이를 보고 알았습니다.)
하지만 이 코드는 효용성 테스트에서는 틀립니다. 모든 info를 도는것이 시간을 잡아먹는거 같습니다.
코드
def solution(info, query):
answer = []
for q in query:
q = (q.replace('and','').split()) # ['cpp', 'backend', 'senior', 'pizza', '260']
print(q)
count = 0
for i in info: # java backend junior pizza 150
i = i.split() #['java', 'backend', 'senior',chicken','50']
flag = True
if ( int(i[4]) < int(q[4]) ):
flag = False
else:
for idx in range(4):
if q[idx] == '-':
continue
else:
if q[idx] != i[idx]:
flag = False
break
if flag == True:
count += 1
answer.append(count)
return answer확인해야할 것은 4가지 뿐입니다. 언어, 포지션, 경력, 음식 을 모두 돌면 됩니다. flag는 점수가 낮거나 다른 글자일 때 False가 되어서 해당 쿼리에 맞지 않는 정보입니다.
다른 분들의 풀이를 보고 배웠습니다.
'-'는 모든 조건을 만족한다는 것으로 이를 포함시켜 조건을 조회할 경우 높은 시간 복잡도를 갖게 된다. 따라서 이를 효율적으로 할 수 있는 방법을 사용해야 한다. 여러 방법이 존재하겠지만, 다음의 성질을 이용하면 보다 낮은 시간 복잡도로 문제를 해결할 수 있다.
java backend junior pizza를 조건으로 갖고 있는 사람의 경우
"java backend junior pizza", "- backend junior, pizza", "java - junior, pizza", "java backend - pizza", "java backend junior -", "- - junior pizza", "- backend - pizza", "- backend junior -", "java - - pizza", "java - junior -", "java backend - -", "- - - pizza", "- - junior -", "- backend - -", "java - - -", "- - - -"
총 16개의 조건에 해당하는 사람이라고 말할 수 있다.
지원자들의 조건으로 만들 수 있는 모든 경우의 수를 key, 해당 지원자의 코딩 테스트 점수를 value로 하는 딕셔너리를 구성하면 조회에 필요한 시간 복잡도를 풀일 수 있다.
코드
from itertools import combinations #모든 경우의 수를 찾아줌
from collections import defaultdict
#defaultdict()는 딕셔너리를 만드는 dict클래스의 서브클래스이다.
# 작동하는 방식은 거의 동일한데, defaultdict()는 인자로 주어진 객체(default-factory)의 기본값을 딕셔너리값의 초깃값으로 지정할 수 있다.
# 숫자, 리스트, 셋등으로 초기화 할 수 있
def solution(info, query):
answer = []
infos = defaultdict(list)
for i in info:
temp = i.split()
conditions = temp[:-1]
score = int(temp[-1])
for n in range(5):
combi = list(combinations(range(4),n)) # [0,1,2,3] , [(0, 1), (0, 2), (0, 3), (1, 2), (1, 3), (2, 3)]...
for c in combi: # [0,1,2,3] , [(0, 1), (0, 2), (0, 3), (1, 2), (1, 3), (2, 3)]...
t_c = conditions.copy() # ['java', 'backend', 'junior', 'chicken'] #
for v in c: # 지원 자들의 조건을 만들 수 있는 모든 경우의 수는 key
t_c[v] = '-' # 0,1,2,3 ~ 01, 02, 03 ~ 123 ~ 0123 ~
print(t_c)
print('-----------')
infos['/'.join(t_c)].append(score)
print(infos)
return answer
solution(["java backend junior pizza 150","python frontend senior chicken 210","python frontend senior chicken 150","cpp backend senior pizza 260","java backend junior chicken 80","python backend senior chicken 50"],
["java and backend and junior and pizza 100","python and frontend and senior and chicken 200","cpp and - and senior and pizza 250","- and backend and senior and - 150","- and - and - and chicken 100","- and - and - and - 150"])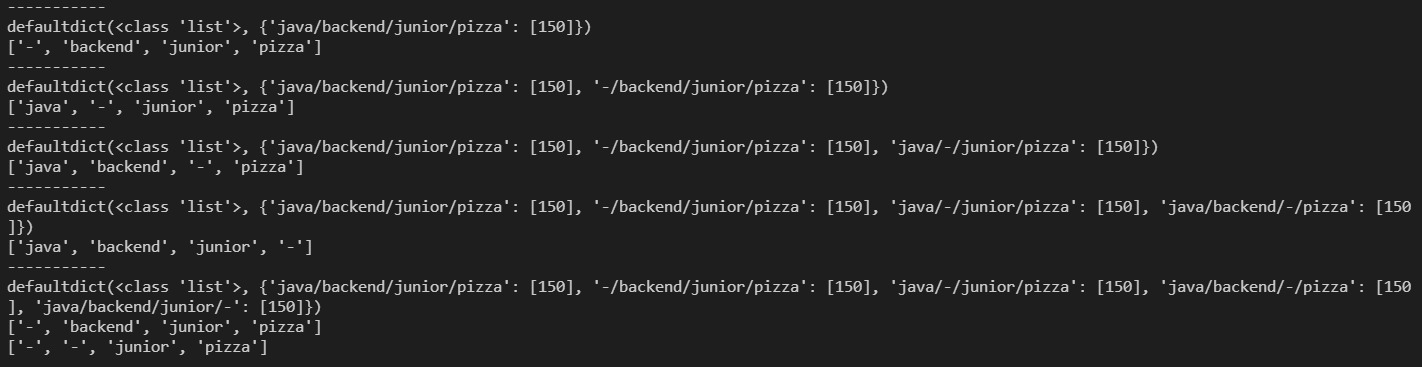
defaultdict 썻습니다. infos라는 딕셔너리에 list 속성을 쓸 수 있게하는 것입니다.
'/'.join(t_c)로 16가지의 경우의 수를 '/'단위로 끊어서 딕셔너리에 넣습니다. 이 때 value는 score입니다. 가지고 있는 score 입니다. score의 값은 변하면 안되죠.
정답인 infos 리스트를 만들어서 query문을 대조하는 방식입니다. query문을 넣어서 정답이면 정답의 개수를 answer에 넣습니다.
ex)

- and - and - and chicken 100
이 query는 chicken이고 100점만 넘으면 됩니다.
먼저 chicken인 info를 가져올 것입니다.
| python | frontend | senior | chicken | 210 |
| python | frontend | senior | chicken | 150 |
| java | backend | junior | chicken | 80 |
| python | backend | senior | chicken | 50 |
여기서 score를 보면 [50, 80, 150, 210]이 될 것 입니다.
이제 이것을 이진 탐색하면 됩니다.
우리는 score를 기준으로 크거나 같은 값을 찾아야 합니다.
먼저 딕셔너리의 모든 score를 sort()합니다.
만들어진 infos를 for문 돌려서 모든 key의 value를 sort()하면 됩니다.
for item in infos:
infos[item].sort()
먼저 중간지점을 잡고 중간 지점이 score 보다 크거나 같다면 score는 더 작다는 의미이니 왼쪽을 탐색합니다. 아니면 오른쪽을 탐색합니다.
for q in query:
q = q.replace('and','').split() # ['java', 'backend', 'junior', 'pizza', '100']
conditions = '/'.join(q[:-1]) # java/backend/junior/pizza
score = int(q[-1]) # 100
if conditions in list(infos): # java/backend/junior/pizza
data = infos[conditions]
print(data)
if(len(data) > 0):
start, end = 0, len(data)
while start != end and start != len(data):
if(data[(start + end) // 2]) >= score: # 왼쪽 탐색
end = (start + end) // 2
else:
start = (start + end) // 2 + 1 # 오른쪽 탐색
answer.append(len(data) - start)
else:
answer.append(0)이분 탐색은 start와 end가 같아지고 0인 start가 배열 끝까지 갔을 때 종료합니다.
참고: https://firsteast.tistory.com/103
https://dev-note-97.tistory.com/131
'알고리즘 > Programmers' 카테고리의 다른 글
| [Programmers / Java] 멀쩡한 사각형 (0) | 2022.05.07 |
|---|---|
| [Programmers / Python] 메뉴 리뉴얼 (0) | 2022.03.04 |
| [Programmers / Python] 괄호변환 (0) | 2022.03.03 |
| [Programmers / Python] 비밀지도 (0) | 2022.02.26 |
| [Programmers / Java] 로또의 최고 순위와 최저 순위 (0) | 2021.12.17 |