이 글은 https://www.youtube.com/watch?v=SBdy0nSctRM&list=PLJN246lAkhQjoU0C4v8FgtbjOIXxSs_4Q&index=15 보고 공부한 글입니다.
지난 시간에

비지도 학습(군집 알고리즘) 을 사용해봤다.
사용자가 나눈 이미지를 분류하는 것이다.
처음에는 샘플별로 행과열에있는 전체 픽셀 평균을 내봤다.
각 픽셀별로 모들 샘플의 평균값을 이미지로 출력해본다.
흐릿한 이미지가 나온다.
저런 흐릿한 평균 이미지와 비슷한 사진을 고르면 진짜 사과사진와 비슷하지 않을까 생각했다.
하지만 픽셀을 구할 때 3개의 과일이 있다는걸 알았다.(타깃값을 알았다.)
군집
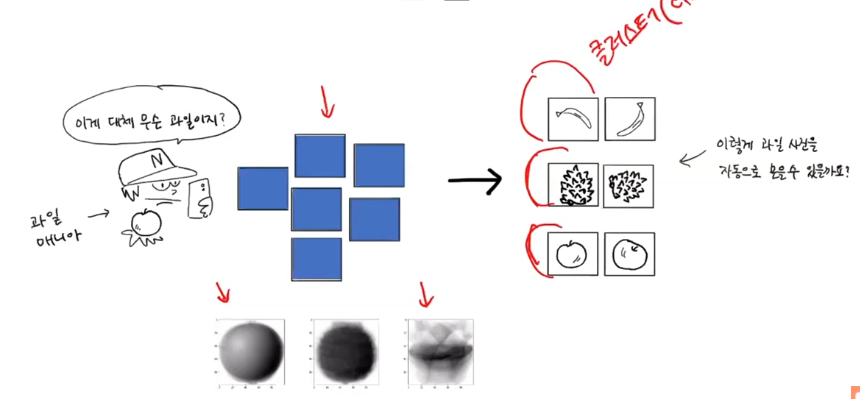
이미지를 하나씩 열어보고 분류할 수 없다.
다 모은 이미지를 클러스터(cluster)라고 부르고 이것을 분류 하는것을 클러스터링이라고 부른다.
중심(평균)을 자동으로 찾는다.
이미지 종류를 모르는데
종류별로 나누는 기준이 중심값이다.
k-평균

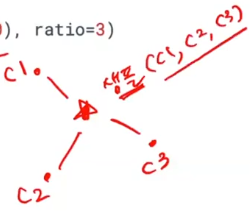
k개의 클러스터를 임의로 정한다.
k=3인 예시이다.(하이퍼 파라미터, 정해야 하는 값이다.)
빨간점으로 3개의 중심을 구한다.
빨간점과 가장 가까운 것을 묶어서 군집을 이룬다.
사과가 2개있으니 중심이 다시 사과쪽으로 이동한다.
바나나가 2개있으니 중심이 다시 바나나쪽으로 이동한다.
파인애플가 2개있으니 중심이 다시 파인애플쪽으로 이동한다.
이런식으로 클러스터가 바뀐다..
모델 훈련

n_clusters로 k개를 설정해준다.
클러스터에서 중심을 센트로이드 라고 부른다.
fit에 훈련데이터를 집어넣는다. 근데 여기서 타깃값이 없다.
과대적합, 과소적합이라는 계념이 아니다.
트리의 질문을 학습해 나가는 것도 아니다.
훈련한 결과는 labels_에 있다.
결과는 0,1,2가 있다. n_clusters를 3으로 지정했기 때문이다.
unique로 0,1,2의 값을 출력받을 수 있다.
0은 91개
1은 98개
2는 111개
10번을 k-평균 작업을 한다음 제일 괜찮은것을 고른다.
첫 번째 클러스터

두 번째, 세 번째 클러스터

클러스터 중심

센트로이드 값은 cluster_centers_에 들어가 있다. 2차원 배열로 되어 있다.
3차원 배열로 바꿔서 draw_fruits()에 넣는다.
0=사과
1=바나나
3=파인애플
로 되어있었다.
transform()은 원본이미지를 다른 데이터셋으로 변환해주는 것이다.
100*100개의 값을 하나하나 3개의 백터로 줄일 수 있다.
즉 3개를 중심값으로 변환 시키는 것이다.
거리가 가까울 수면 클러스터에 값을 지정해준다.
n_iter_는 반복횟수이다.
클러스터를 묶고 중심이동하고 클러스터를 묶고 중심이동하는 것을 3번 반복한 것이다.
최적의 k 찾기

좋은 k값을 찾는 방법은 엘보우 메소드를 사용하는 것이다.
2~7까지 차례대로 군집을 설정해본다.
inertia_는 클러스터의 중심에서 클러스터의 요소 까지의 거리를 평균낸 것이다.
조밀하게 모여있다면 inertia_값이 줄어들것이다.
그래프를 보면 딱 꺽인 값이 있다. 그것을 이 이후에 k값을 늘려도 큰변화가 없다는 의미이다.
원형의 클러스터가 만들어진다.
'머신러닝 > 혼자 공부하는 머신러닝' 카테고리의 다른 글
| 17강 인공 신경망 -> 간단한 인공 신경망 모델 만들기 (0) | 2021.07.13 |
|---|---|
| 16강 주성분 분석: 차원 축소 알고리즘 PCA 모델 만들기 (0) | 2021.07.12 |
| 14강 흑백 이미지 분류 방법과 비지도 학습, 군집 알고리즘 이해하기 (0) | 2021.07.10 |
| 13강 트리의 앙상블 (0) | 2021.07.09 |
| 12강 교차 검증과 그리드 서치 (0) | 2021.07.08 |



