이 글은 https://www.youtube.com/watch?v=tOzxDGp8rsg&list=PLJN246lAkhQjoU0C4v8FgtbjOIXxSs_4Q&index=11 보고 공부한 글입니다.
지난 시간에

손실함수 - 모델이 얼마나 실수하는지
손실함수는 낮을 수록 좋다.
분류에서는 손실함수를 로지스틱 함수로 쓴다.
레드 와인과 화이트 와인
캔안에 든 음료가 레드인지 화이트 인지 알아보자.
알코올, 당도, ph만 알고 알아보자.
화이트와인: 양성(1)
레드와인: 음성(0)

데이터 준비하기

wine = 데이터 프레임
info()는 데이터의 타입, 데이터 프레임의 크기를 알려준다.
Non-null count은 알코올에 누락된 값이 1개 있다면 6496이 될것이다.
즉, 널이 있다는 것은 빈 자료가 있다는 것이다.
max 결과를 보면 각각 스케일이 다르다. 2자리수도 있고 1자리수도 있다. 스케일을 맞춰줘야 한다.

로지스틱 회귀

taret은 class에 들어있다 레드와인 인지 화이트인지 구분하는 것이다.
3개의 특성을 사용했으니 3개 특성에 곱해지는 값들이 coef_에 있다.
coef_를 해석해보면
입력값이 양수라고 했을때
알코올, 당도가 많을 수록 화이트와인 될 가능성이 있다.
ph가 높을 수록 레드와인이 될 가능성이 있다.
쉽게 애기하는 방법을 알아보자
결정트리
사이킷런 밑에 tree모듈에 있다.

분류 = classifier
회귀 = Regression
사용법은 로지스틱 회귀와 똑같다.
객체의 매개변수에 max_features가 있다.
사용할 특성의 갯수를 정한다. 기본값이 None이니 우리는 3개를 사용하고 있다.
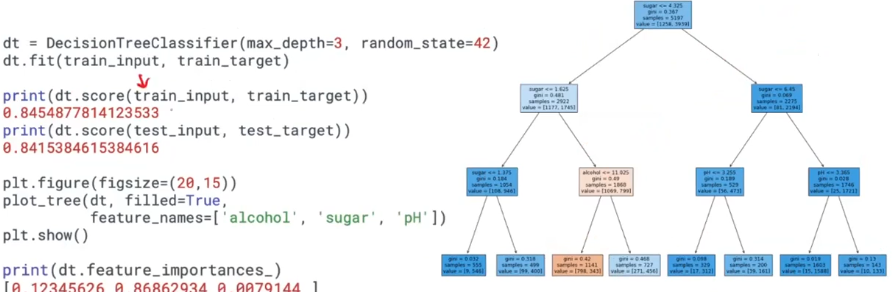
정확도를 보면 로지스틱보다 훨씬 높다.
테스트 세트는 낮다.
plot_tree에 객체를 넣어주면 그래프를 볼 수 있다.
맨 끝에 리프노드에 도달하면 레드, 화이트를 구분할 수 있다.
루트에 x를 넣으면 질문을 따라간다.
리프노드에 대한 예측이 x에 대한 예측이다.
분류일 때는 최근접 이웃과 비슷하다.
마지막 리프노드에 들어있는 다수의 클래스들이 예측클래스가 된다.
회귀일 때
마지막 리프노드에 있는 타겟값의 평균이 x의 예측값이 된다.
결정트리 분석
트리사이즈를 줄여서 자세히 보자.
max_features가 2일 때는 알코올,ph,당도중에 2개만 선택을 할 것이다.

filled 가 true이면 양성클래스는 파란색으로 , 음성클래스는 묽은색으로 표현해서 시각적으로 한눈에 볼 수 있다.
feature_names를 주면 특성을 그래프에 표현해준다.
네모박스를 전부 노드라고 부른다.
처음에는 sugar로 나눴다.
5197개중에 2922가 왼쪽으로 2275가 오른쪽으로 갔다.
value는 5197의 음성클래스와 양성클래스의 갯수이다.
gini = 불순도 기준
지니 불순도

사이킷런에 디시전클래시파이어 트리에 criterion이 있다.
기준을 정하는건데 어떤 기준으로 노드를 분할 할거냐 이것을 gini로 쓴다.
criterion = 'gini'
계산하는 방법은 1에서 (음성클래스비율을 제곱 + 양성클래스비율 제곱)을 빼면 된다.
부모의 지니 불순도와 자식의 지니 불순도의 값을 뺐을 때 값이 가장 크게나오는 방향으로 노드는 분할한다.
불순도 0.5가 가장 분순한 것이다.
0인 것은 양성클래스로만 이루어 진것이다. 이를 순수노드라고 부른다.
리프노드가 모두 순수노드가 될 때까지 분할 한다.

이렇게 해서 계산하는 것이 부모노드와 자식노드의 불순도 차이를 계산하는 것이다.
가지치기
순수노드로 가기위해서 너무많은 트리로 분할되면 안된다.

막기위해서 max_depth를 사용한다.
예시는 트리의 깊이를 3으로 제한한 것이다.
훈련세트와 테스트 세트간에 차이는 줄어들었다.
과대적합, 과소적합을 막은 것이다.
L2, L2규제, 선형함수 를 적용할 수 없으니

레드와인은 주황색으로 표시되어 있다.
스케일 조정하지 않은 특성 사용하기
전처리가 필요 없다!
전처리 한 값과 동일하게 나온다.
특성 중요도(feature_importances_)를 출력해준다.
훈련세트로부터 학습한 값
각 특성마다 값을 준다.
sugar가 가장 중요하게 사용된다는 것을 알 수 있다.
트리를 가지고 앙상블 모델을 만들 수 있다.
'머신러닝 > 혼자 공부하는 머신러닝' 카테고리의 다른 글
| 13강 트리의 앙상블 (0) | 2021.07.09 |
|---|---|
| 12강 교차 검증과 그리드 서치 (0) | 2021.07.08 |
| 10강 확률적 경사 하강법 알아보기 (0) | 2021.07.06 |
| 9강 로지스틱 회귀 알아보기 (0) | 2021.07.05 |
| 8강 특성 공학과 규제 알아보기 (0) | 2021.07.04 |



