이 글은 https://www.youtube.com/watch?v=xkknXJeEaVA&list=PLVsNizTWUw7HpqmdphX9hgyWl15nobgQX&index=7 보고 공부한 글입니다.

지난 시간에 배운 것이다.
회귀는 임의의 어떤 숫자를 예측하는 것이다.
물고기의 종류를 묻는 것이 아닌 무게를 보는 것이다.
k-최근접 이웃 회귀 알고리즘을 썻다.
회귀에서 타겟의 값은 임의의 숫자가 된다.
타겟과 예측값의 차이로 결과를 낸다.
k-최근접 이웃 회귀 문제가 있다!

50cm 농어를 넣었는데 1033g 인 무개가 나왔다.
근데 알고보니 1.5kg 이다!
왜 이런 문제가 나올까?
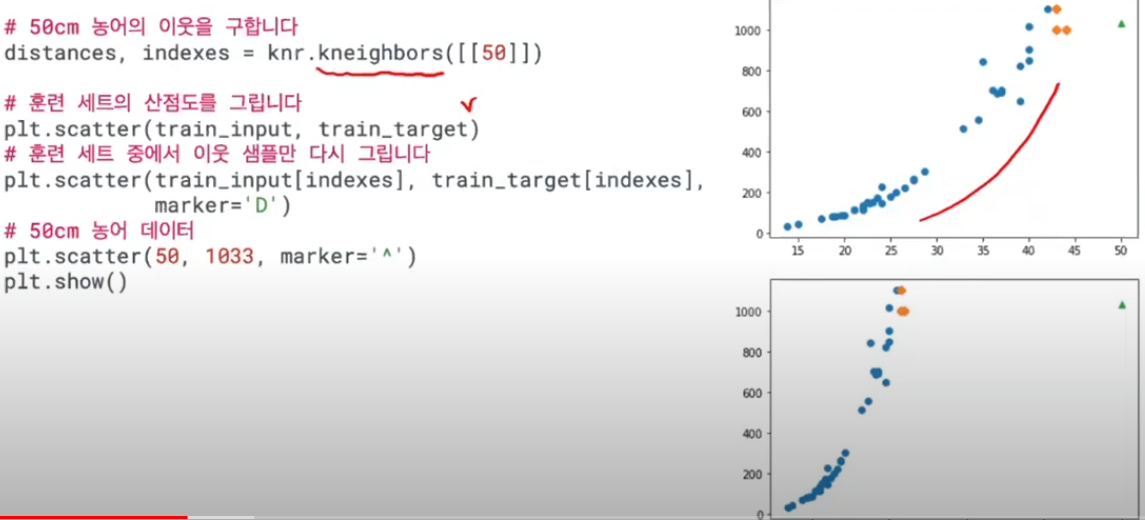
50의 이웃의 인덱스를 구한다. -> 그래프에 그린다.
예를 들어 100cm인 큰 생선도 최대값이 40cm가 이웃이다.
k-최근접 회귀 알고리즘은 훈련 세트 범위 밖 샘플을 예상하기 어렵다!
이 문제를 해결하기 위해 선형 회귀를 사용해보자
linear regession

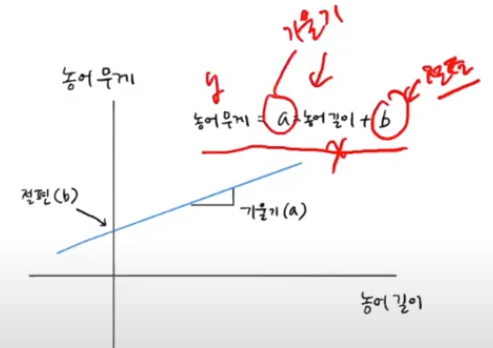
1차원 데이터만 있을때 직선의 방정식(1차식)을 구한다.
3번째 그래프 그림의 직선을 찾는 방정식이 선형회귀 이다.
linearRegression

사이킷런에 선형회귀가 있다.
선형모델을 만들고 50cm 농어를 줬더니 1241g이 나온다.
최근접 이웃보다는 나은 값이 나왔다.
직선을 학습한 것이다.
농어의 무게 = y
농어의 길이 = x
하면 농어의 길이에 따른 무게가 나올 것이다.
기울기과 절편은 .coef_, intercept_ 에 저장되어 있다.
기울기는 numpy array로 되어 있다. 특성이 더 많아 질 수 있다.
다른 속성과 구분되라고 끝에 _ 가 붙어있다. (= 모델이 학습한 값)
학습한 직선 그리기

scatter로 훈련 세트를 그린다.
15~50까지의 1차방정식 그래프를 그린다.
x좌표 = 15*기울기+절편
y좌룦 = 50*기울기+절편
테스트 세트 점수가 너무 낮다.
왼쪽 끝에 0보다 작은 수가 그려질 수 있다.
절편(intercept_)가 음수로 나왔다.
직선포다는 2차 함수로 만들면 더 좋을 것이다.
다항 회귀

길이는 알고 있으니 길이의 제곱을 만들어서
새로운 열을 만든다.
1열에는 길이의 제곱, 2열에는 그냥 길이가 있다.
훈련세트, 테스트 세트를 만든다.
모델 다시 훈련

길이의 제곱과 길이의 행렬을 input으로 넣어둔다.
처음에 했던 훈련 세트 input은 (42,1)이지만 이건 (42,2)이다.
50cm 농어를 예측할 때 50만 넣어주면 안되고 50의 제곱도 넣어줘야 한다.
1573g의 예측값을 출력했다.
모델의 훈련한 방정식의 값은
y= 1.01*x^2 - 21.6*x+ 116.05
이다.
학습한 직선 그리기

직선을 잘게 짤라서 곡선처럼 보이게 한다.
15~49까지 포인트 배열을 만든다.
polt = 방정식 그리기
훈련 세트와 테스트 세트의 균형이 맞으니 모델의 성능이 높아졌다고 할 수 있다.
'머신러닝 > 혼자 공부하는 머신러닝' 카테고리의 다른 글
| 9강 로지스틱 회귀 알아보기 (0) | 2021.07.05 |
|---|---|
| 8강 특성 공학과 규제 알아보기 (0) | 2021.07.04 |
| 6강 회귀 문제를 이해하고 k-최근접 이웃 알고리즘으로 풀어 보기 (0) | 2021.07.02 |
| 5강 정교한 결과 도출을 위한 데이터 전처리 알아보기 (0) | 2021.07.01 |
| 4강 훈련 세트와 테스트 세트로 나누어 사용하기 (0) | 2021.06.30 |



